
Извлечение текста из файла является обычной задачей в сценариях и программировании, и Python делает это легко. В этом руководстве мы обсудим несколько простых способов извлечения текста из файла с использованием языка программирования Python 3.
- Убедитесь, что вы используете Python 3.
- Чтение данных из текстового файла.
- Использование «с открытым».
- Чтение текстовых файлов построчно.
- Хранение текстовых данных в переменной.
- Поиск текста для подстроки.
- Включая регулярные выражения.
- Собираем все вместе.
Убедитесь, что вы используете Python 3
В этом руководстве мы будем использовать Python версии 3. Большинство систем поставляется с Python 2.7. В то время как Python 2.7 используется в большинстве устаревших кодов, Python 3 является настоящим и будущим языка Python. Если у вас нет особых причин писать или поддерживать устаревший код Python, мы рекомендуем работать в Python 3.
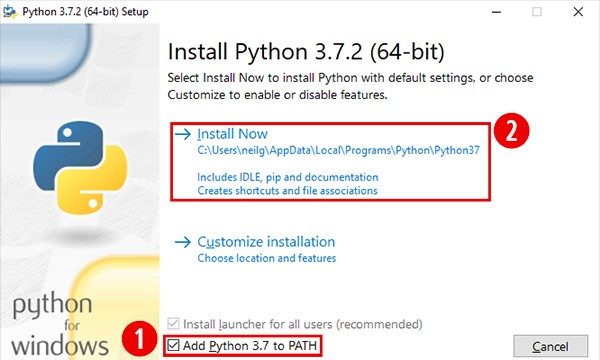
Для Microsoft Windows Python 3 можно загрузить с https://www.python.org. При установке убедитесь, что оба параметра «Install launcher for all users» и «Add Python to PATH» отмечены, как показано на рисунке ниже.
В Linux вы можете установить Python 3 с вашим менеджером пакетов. Например, в Debian или Ubuntu вы можете установить его с помощью следующей команды:
sudo apt-get update sudo apt-get установить python3
Для macOS установщик Python 3 можно загрузить с python.org, как указано выше. Если вы используете менеджер пакетов Homebrew, его также можно установить, открыв окно терминала (Приложения → Утилиты) и выполнив следующую команду:
заварить установить python3
Запуск Python
В Linux и macOS команда для запуска интерпретатора Python 3 — это python3. В Windows, если вы установили модуль запуска, команда py. Команды на этой странице используют python3; если вы работаете в Windows, замените py на python3 во всех командах.
Запуск Python без опций запустит интерактивный интерпретатор. Для получения дополнительной информации об использовании интерпретатора см. Обзор Python: использование интерпретатора Python. Если вы случайно вошли в интерпретатор, вы можете выйти из него с помощью команды exit () или quit ().
Запуск Python с именем файла будет интерпретировать эту программу на Python. Например:
python3 program.py
…запускает программу, содержащуюся в файле program.py.
Хорошо, как мы можем использовать Python для извлечения текста из текстового файла?
Чтение данных из текстового файла
Сначала давайте прочитаем текстовый файл. Допустим, мы работаем с файлом с именем lorem.txt, который содержит несколько строк латиницы:
Lorem Ipsum Dolor Sit Amet, Concetetur Adipiscing Elit.
Mauris nec maximus purus. Меценаты сидят на месте.
Quisque в dignissim lacus.
Заметка
Во всех приведенных ниже примерах мы работаем с текстом, содержащимся в этом файле. Не стесняйтесь копировать и вставлять указанный выше латинский текст в текстовый файл и сохранять его как lorem.txt, чтобы вы могли запустить пример кода, используя этот файл в качестве входных данных.
Программа Python может читать текстовый файл, используя встроенную функцию open (). Например, ниже приведена программа на Python 3, которая открывает файл lorem.txt для чтения в текстовом режиме, считывает содержимое в строковую переменную с именем content, закрывает файл и затем печатает данные.
myfile = open ("lorem.txt", "rt") # open lorem.txt для чтения текста
contents = myfile.read () # прочитать весь файл в строку
myfile.close () # закрыть файл
печать (содержание) # печать содержимогоЗдесь myfile — это имя, которое мы даем нашему объекту file.
Параметр «rt» в функции open () означает «мы открываем этот файл для чтения текстовых данных»
Метка хеша («#») означает, что все остальное в этой строке является комментарием и игнорируется интерпретатором Python.
Если вы сохраните эту программу в файле с именем read.py, вы можете запустить ее с помощью следующей команды.
python3 read.py
Команда выше выводит содержимое файла lorem.txt:
Lorem Ipsum Dolor Sit Amet, Concetetur Adipiscing Elit.
Mauris nec maximus purus. Меценаты сидят на месте.
Quisque в dignissim lacus.
Использование «с открытым»
Важно как можно скорее закрыть открытые файлы: открыть файл, выполнить операцию и закрыть его. Не оставляйте это открытым в течение длительных периодов времени.
Когда вы работаете с файлами, рекомендуется использовать с открытым … в качестве составного оператора. Это самый чистый способ открыть файл, работать с ним и закрыть файл в одном легко читаемом блоке кода. Файл автоматически закрывается после завершения блока кода.
Используя open … as, мы можем переписать нашу программу так:
с открытым ('lorem.txt', 'rt') в качестве myfile: # Открыть lorem.txt для чтения текста
contents = myfile.read () # Читать весь файл в строку
print (содержимое) # Распечатать строкуЗаметка
Отступ важен в Python. Программы Python используют пробелы в начале строки для определения области видимости, например, блока кода. Рекомендуется использовать четыре пробела на уровень отступа и использовать пробелы, а не символы табуляции. В следующих примерах убедитесь, что ваш код имеет отступ в точности так, как он представлен здесь.
пример
Сохраните программу как read.py и выполните ее:
python3 read.py
Выход
Lorem Ipsum Dolor Sit Amet, Concetetur Adipiscing Elit.
Mauris nec maximus purus. Меценаты сидят на месте.
Quisque в dignissim lacus.
Чтение текстовых файлов построчно
До сих пор в примерах мы читали весь файл сразу. Чтение полного файла не имеет большого значения для маленьких файлов, но, вообще говоря, это не очень хорошая идея. С одной стороны, если ваш файл больше, чем объем доступной памяти, вы столкнетесь с ошибкой.
Почти в каждом случае лучше читать текстовые файлы по одной строке за раз.
В Python файловый объект является итератором. Итератор — это тип объекта Python, который ведет себя определенным образом при многократном использовании. Например, вы можете использовать цикл for для многократной работы с файловым объектом, и каждый раз, когда выполняется одна и та же операция, вы получите другой, или «следующий», результат.
пример
Для текстовых файлов объект файла повторяет одну строку текста за раз. Он считает одну строку текста «единицей» данных, поэтому мы можем использовать оператор цикла for … in для итерации данных по одной строке за раз:
с открытым ('lorem.txt', 'rt') в качестве myfile: # Открыть файл lorem.txt для чтения текста
для myline в myfile: # Для каждой строки читайте ее в строку
print (myline) # напечатать эту строку, повторитьВыход
Lorem Ipsum Dolor Sit Amet, Concetetur Adipiscing Elit. Mauris nec maximus purus. Меценаты сидят на месте. Quisque в dignissim lacus.
Обратите внимание, что мы получаем дополнительный разрыв строки («новая строка») после каждой строки. Это потому, что печатаются две новые строки. Первый — это новая строка в конце каждой строки нашего текстового файла. Второй перевод строки происходит потому, что по умолчанию print () добавляет собственный разрыв строки в конце того, что вы просили напечатать.
Давайте сохраним наши строки текста в переменной, в частности, в переменной списка, чтобы мы могли взглянуть на нее более внимательно.
Хранение текстовых данных в переменной списка
В Python списки похожи, но не совпадают с массивами в C или Java. Список Python содержит индексированные данные различной длины и типов.
пример
mylines = [] # Объявить пустой список с именем mylines.
с открытым ('lorem.txt', 'rt') в качестве myfile: # Откройте lorem.txt для чтения текстовых данных.
для myline в myfile: # Для каждой строки, сохраненной как myline,
mylines.append (myline) # добавляет его содержимое в mylines.
print (mylines) # Распечатать список.Вывод этой программы немного другой. Вместо того, чтобы печатать содержимое списка, эта программа печатает наш объект списка, который выглядит следующим образом:
Выход
['Lorem Ipsum Dolor Sit Amet, Concetetur Adipiscing Elit. Nunc fringilla arcu congue metus aliquam mollis. \ N ',' Mauris nec maximus purus. Меценаты сидят на месте. Praesent Sed Rhoncus EO. Duis id Commodo orci. \ N ',' Quisque at dignissim lacus. \ N ']
Здесь мы видим необработанное содержимое списка. В необработанном виде объекта список представляется в виде списка, разделенного запятыми. Здесь каждый элемент представлен в виде строки, а каждая новая строка представлена в виде последовательности escape-символов \ n.
Подобно массиву в C или Java, мы можем получить доступ к элементам списка, указав номер индекса после имени переменной в скобках. Индексные номера начинаются с нуля — другими словами, n-й элемент списка имеет числовой индекс n-1.
Заметка
Если вам интересно, почему номера индексов начинаются с нуля, а не с одного, вы не одиноки. Компьютерные ученые обсуждали полезность систем нумерации с нуля в прошлом. В 1982 году Эдсгер Дейкстра высказал свое мнение по этому вопросу, объяснив, почему нумерация с нуля является лучшим способом индексации данных в информатике. Вы можете прочитать памятку самостоятельно — он приводит убедительные аргументы.
пример
Мы можем напечатать первый элемент строк, указав номер индекса 0, заключенный в скобки после названия списка:
Печать (mylines [0])
Выход
Lorem Ipsum Dolor Sit Amet, Concetetur Adipiscing Elit. Nunc fringilla arcu congue metus aliquam mollis.
пример
Или третья строка, указав номер индекса 2:
печать (mylines [2])
Выход
Quisque в dignissim lacus.
Но если мы пытаемся получить доступ к индексу, для которого нет значения, мы получим ошибку:
пример
Печать (mylines [3])
Выход
Traceback (последний вызов был последним): Файл, строка, в Печать (mylines [3]) IndexError: список индексов вне диапазона
пример
Объект списка является итератором, поэтому для печати каждого элемента списка мы можем выполнить итерацию по нему с помощью for … in:
mylines = [] # Объявить пустой список
с открытым ('lorem.txt', 'rt') в качестве myfile: # Откройте lorem.txt для чтения текста.
для строки в myfile: # Для каждой строки текста,
mylines.append (line) # добавляет эту строку в список.
для элемента в mylines: # Для каждого элемента в списке,
print (element) # напечатать это.Выход
Lorem Ipsum Dolor Sit Amet, Concetetur Adipiscing Elit. Mauris nec maximus purus. Меценаты сидят на месте. Quisque в dignissim lacus.
Но мы все еще получаем дополнительные новые строки. Каждая строка нашего текстового файла заканчивается символом новой строки (‘\ n’), который печатается. Кроме того, после печати каждой строки print () добавляет собственную новую строку, если вы не скажете, чтобы она делала иначе.
Мы можем изменить это поведение по умолчанию, указав конечный параметр в нашем вызове print ():
print (element, end = '')
Устанавливая в конце end пустую строку (представленную в виде двух одинарных кавычек, без пробелов), мы говорим print () ничего не печатать в конце строки вместо символа новой строки.
пример
Наша пересмотренная программа выглядит так:
mylines = [] # Объявить пустой список
с открытым ('lorem.txt', 'rt') в качестве myfile: # Открыть файл lorem.txt для чтения текста
для строки в myfile: # Для каждой строки текста,
mylines.append (line) # добавляет эту строку в список.
для элемента в mylines: # Для каждого элемента в списке,
print (element, end = '') # напечатать его, без дополнительных переносов.Выход
Lorem Ipsum Dolor Sit Amet, Concetetur Adipiscing Elit.
Mauris nec maximus purus. Меценаты сидят на месте.
Quisque в dignissim lacus.
Новые строки, которые вы видите здесь, на самом деле находятся в файле; это специальный символ (‘\ n’) в конце каждой строки. Мы хотим избавиться от них, поэтому нам не нужно беспокоиться о них, пока мы обрабатываем файл.
Как убрать переводы строки
Чтобы полностью удалить новые строки, мы можем их убрать. Чтобы удалить строку, необходимо удалить один или несколько символов, обычно пробелов, из начала или конца строки.
Чаевые
Этот процесс иногда также называют «обрезкой».
Строковые объекты Python 3 имеют метод rstrip (), который удаляет символы с правой стороны строки. Английский язык читается слева направо, поэтому зачистка с правой стороны удаляет символы с конца.
Если переменная называется mystring, мы можем удалить ее правую часть с помощью mystring.rstrip (chars), где chars — это строка символов для удаления. Например, «123abc» .rstrip («bc») возвращает 123a.
Чаевые
Когда вы представляете строку в вашей программе с ее литеральным содержимым, она называется строковым литералом. В Python (как и в большинстве языков программирования) строковые литералы всегда заключаются в кавычки — заключенные с обеих сторон одинарными (‘) или двойными («) кавычками. В Python одинарные и двойные кавычки эквивалентны; вы можете использовать одну или другую, до тех пор, пока они совпадают на обоих концах строки. Традиционно представлять удобочитаемую строку (например, Hello) в двойных кавычках («Hello»). Если вы представляете один символ (например, b), или один специальный символ, такой как символ новой строки (), традиционно использовать одинарные кавычки (‘b’, »). Для получения дополнительной информации о том, как использовать строки в Python, вы можете прочитать документацию по строкам в Python.
Оператор string.rstrip (‘\ n’) удалит символ новой строки с правой стороны строки. Следующая версия нашей программы удаляет символы новой строки, когда каждая строка читается из текстового файла:
mylines = [] # Объявить пустой список.
с открытым ('lorem.txt', 'rt') в качестве myfile: # Откройте lorem.txt для чтения текста.
для myline в myfile: # Для каждой строки в файле,
mylines.append (myline.rstrip ('\ n')) # удалите новую строку и добавьте в список.
для элемента в mylines: # Для каждого элемента в списке,
print (element) # напечатать это.Текст теперь сохраняется в переменной списка, поэтому отдельные строки могут быть доступны по номеру индекса. Новые строки были удалены, поэтому нам не о чем беспокоиться. Мы всегда можем вернуть их позже, если мы восстановим файл и запишем его на диск.
Теперь давайте поищем строки в списке для определенной подстроки.
Поиск текста для подстроки
Допустим, мы хотим найти каждое вхождение определенной фразы или даже одной буквы. Например, может быть, нам нужно знать, где находится каждое «е». Мы можем сделать это используя метод find () для строки.
Список хранит каждую строку нашего текста как строковый объект. Все строковые объекты имеют метод find (), который находит первое вхождение подстроки в строке.
Давайте использовать метод find () для поиска буквы «e» в первой строке нашего текстового файла, который хранится в списке mylines. Первый элемент mylines — строковый объект, содержащий первую строку текстового файла. Этот строковый объект имеет метод find ().
В скобках find () мы указываем параметры. Первый и единственный обязательный параметр — это строка для поиска, «e». Оператор mylines [0] .find («e») говорит интерпретатору начинать с начала строки и искать вперед, по одному символу за раз, пока не найдет букву «e». Когда он находит его, он прекращает поиск и возвращает номер индекса, где находится это «е». Если он достигает конца строки, он возвращает -1, чтобы указать, что ничего не найдено.
пример
печать (mylines [0] .find ( "е"))
Выход
3
Возвращаемое значение «3» говорит нам, что буква «е» является четвертым символом, «е» в «Lorem». (Помните, индекс начинается с нуля: индекс 0 — это первый символ, 1 — второй и т. Д.)
Метод find () принимает два необязательных дополнительных параметра: начальный индекс и конечный индекс, указывающие, где в строке должен начинаться и заканчиваться поиск. Например, string.find («abc», 10, 20) будет искать подстроку «abc», но только с 11-го по 21-й символ. Если stop не указан, find () будет начинаться с начала индекса и останавливаться в конце строки.
пример
Например, следующий оператор ищет «e» в mylines [0], начиная с пятого символа.
print (mylines [0] .find ("e", 4))Выход
24
Другими словами, начиная с 5-го символа в строке [0], первое «е» находится в индексе 24 («е» в «nec»).
пример
Чтобы начать поиск с индекса 10 и остановиться на индексе 30:
print (mylines [1] .find ("e", 10, 30))Выход
28
(Первое «е» в «Меценатах»).
пример
Если find () не находит подстроку в диапазоне поиска, она возвращает число -1, что указывает на ошибку:
print (mylines [0] .find ("e", 25, 30))Выход
-1
Между индексами 25 и 30 не было никаких «е».
Поиск всех вхождений подстроки
Но что, если мы хотим найти каждое вхождение подстроки, а не только первую, с которой мы сталкиваемся? Мы можем перебрать строку, начиная с индекса предыдущего совпадения.
В этом примере мы будем использовать цикл while, чтобы повторно найти букву «e». Когда вхождение найдено, мы снова вызываем find, начиная с нового местоположения в строке. В частности, местоположение последнего вхождения плюс длина строки (чтобы мы могли двигаться вперед за последним). Когда find возвращает -1 или начальный индекс превышает длину строки, мы останавливаемся.
пример
# Создайте mylines, как показано выше
mylines = [] # Объявить пустой список.
с открытым ('lorem.txt', 'rt') в качестве myfile: # Откройте lorem.txt для чтения текста.
для myline в myfile: # Для каждой строки в файле,
mylines.append (myline.rstrip ('\ n')) # удалите новую строку и добавьте в список.
# Найдите и распечатайте все вхождения буквы «е»
index = 0 # текущий индекс
prev = 0 # предыдущий индекс
str = mylines [0] # строка для поиска (первый элемент mylines)
substr = "e" # подстрока для поиска
в то время как index = len (str))
print ('\ n' + str); # Распечатать оригинальную строку под еВыход
э э э э Lorem Ipsum Dolor Sit Amet, Concetetur Adipiscing Elit. е е Nunc fringilla arcu congue metus aliquam mollis.
Включая регулярные выражения
Для сложных поисков вы должны использовать регулярные выражения.
Модуль регулярных выражений Python называется re. Чтобы использовать его в своей программе, импортируйте модуль перед использованием:
импорт ре
Модуль re реализует регулярные выражения путем компиляции шаблона поиска в объект шаблона. Методы этого объекта могут затем использоваться для выполнения операций сопоставления.
Например, допустим, вы хотите найти любое слово в вашем документе, которое начинается с буквы d и заканчивается буквой r. Мы можем сделать это с помощью регулярного выражения «\ bd \ w * r \ b». Что это значит?
| \ б | Граница слова соответствует пустой строке (что угодно, в том числе вообще ничего), но только если она появляется перед или после несловесного символа. «Символы слова» — это цифры от 0 до 9, строчные и прописные буквы или подчеркивание («_»). |
| d | Строчная буква d. |
| \ Ш * | \ w представляет любой символ слова, а * — это квантификатор, означающий «ноль или более от предыдущего символа». Таким образом, \ w * будет соответствовать нулю или большему количеству слов. |
| р | Строчная буква r. |
| \ б | Граница слова. |
Таким образом, это регулярное выражение будет соответствовать любой строке, которая может быть описана как «граница слова, затем строчная буква d, затем ноль или более символов слова, затем строчная буква r, затем граница слова». Строки, которые могут быть описаны таким образом, включают слова разрушитель, суровый и доктор, а также сокращение д-р.
Чтобы использовать это регулярное выражение в операциях поиска Python, мы сначала скомпилируем его в объект шаблона. Например, следующий оператор Python создает объект шаблона с именем pattern, который мы можем использовать для поиска с использованием этого регулярного выражения.
pattern = re.compile (r "\ bd \ w * r \ b")
Заметка
Буква r перед нашей строкой в приведенном выше утверждении важна. Он говорит Python интерпретировать нашу строку как необработанную строку в точности так, как мы ее набрали. Если бы мы не добавляли строку к r, Python интерпретировал бы escape-последовательности, такие как \ b, другими способами. Всякий раз, когда вам нужно, чтобы Python интерпретировал ваши строки буквально, укажите его как необработанную строку, добавив к ней префикс r.
Теперь мы можем использовать методы объекта шаблона, такие как search (), чтобы искать строку для скомпилированного регулярного выражения, ища совпадение. Если он найдет его, он вернет специальный результат, называемый объектом сопоставления. В противном случае он возвращает None, встроенную константу Python, которая используется как логическое значение «false».
пример
импорт ре str = "Доброе утро, доктор." pat = re.compile (r "\ bd \ w * r \ b") # скомпилировать регулярное выражение "\ bd \ w * r \ b" для объекта шаблона if pat.search (str)! = Нет: # Поиск шаблона. Если найден, печать («нашел его»)
Выход
Нашел это.
пример
Чтобы выполнить поиск без учета регистра, вы можете указать специальную константу re.IGNORECASE на этапе компиляции:
импорт ре str = "Здравствуйте, DoctoR." pat = re.compile (r "\ bd \ w * r \ b", re.IGNORECASE) # совпадут прописные и строчные буквы if pat.search (str)! = Нет: печать («нашел его»)
Выход
Нашел это.
Собираем все вместе
Итак, теперь мы знаем, как открыть файл, прочитать строки в списке и найти подстроку в любом элементе этого списка. Давайте использовать эти знания для создания некоторых примеров программ.
Распечатать все строки, содержащие подстроку
Программа ниже читает файл журнала построчно. Если строка содержит слово «ошибка», она добавляется в список, называемый ошибками. Если нет, то это игнорируется. Строковый метод lower () преобразует все строки в нижний регистр для целей сравнения, что делает поиск регистронезависимым без изменения исходных строк.
Обратите внимание, что метод find () вызывается непосредственно из результата метода lower (); это называется метод цепочки. Также обратите внимание, что в операторе print () мы создаем выходную строку, объединяя несколько строк с помощью оператора +.
пример
errors = [] # Список, где мы будем хранить результаты.
белье = 0
substr = "error" .lower () # Подстрока для поиска.
с открытым ('logfile.txt', 'rt') в качестве myfile:
для строки в myfile:
белье + = 1
if line.lower (). find (substr)! = -1: # если регистр не учитывается,
errors.append ("Line" + str (linenum) + ":" + line.rstrip ('\ n'))
из-за ошибки в ошибках:
печать (ERR)Пример ввода (текстовый файл logfile.txt)
Это строка 1 Это строка 2 В строке 3 произошла ошибка! Это строка 4 В строке 5 также есть ошибка!
Пример вывода
Строка 3: Строка 3 имеет ошибку! Строка 5: Строка 5 также имеет ошибку!
Извлечь все строки, содержащие подстроку, используя регулярное выражение
Приведенная ниже программа похожа на указанную выше, но использует модуль регулярных выражений. Ошибки и номера строк хранятся в виде кортежей, например (белья, строки). Кортеж создается с помощью дополнительных заключающих скобок в операторе errors.append (). Ссылки на элементы кортежа аналогичны списку с индексом, начинающимся с нуля в скобках. Как построено здесь, err [0] — это полотно, а err [1] — связанная строка, содержащая ошибку.
пример
импорт ре
ошибки = []
белье = 0
pattern = re.compile ("error", re.IGNORECASE) # Скомпилировать регулярное выражение без учета регистра
с открытым ('logfile.txt', 'rt') в качестве myfile:
для строки в myfile:
белье + = 1
if pattern.search (line)! = Нет: # Если совпадение найдено
errors.append ((белье, line.rstrip ('\ n')))
из-за ошибки в ошибках: # Перебрать список кортежей
print ("Line" + str (err [0]) + ":" + err [1])Выход (так же, как выше)
Строка 6: 28 марта, 09:10:37 Ошибка: невозможно связаться с сервером. В соединении отказано. Строка 10: 28 марта 10:28:15 Ошибка ядра: указанное местоположение не смонтировано. Строка 14: 28 марта 11:06:30 ОШИБКА: usb 1-1: невозможно установить конфигурацию, выход.
Извлечь все строки, содержащие номер телефона
Программа ниже печатает любую строку текстового файла, info.txt, который содержит номер телефона в США или за рубежом. Это достигается с помощью регулярного выражения «(\ + \ d {1,2})? [\ S .-]? \ D {3} [\ s .-]? \ D {4}». Это регулярное выражение соответствует следующим обозначениям номера телефона:
- 123-456-7890
- (123) 456-7890
- 123 456 7890
- 123.456.7890
- +91 (123) 456-7890
импорт ре
ошибки = []
белье = 0
pattern = re.compile (r "(\ + \ d {1,2})? [\ s .-]? \ d {3} [\ s .-]? \ d {4}")
с открытым ('info.txt', 'rt') в качестве myfile:
для строки в myfile:
белье + = 1
if pattern.search (line)! = None: # Если поиск по шаблону находит совпадение,
errors.append ((белье, line.rstrip ('\ n')))
из-за ошибки в ошибках:
print ("Line", str (err [0]), ":" + err [1])Выход
Строка 3: мой номер телефона 731.215.8881. Строка 7: Вы можете связаться с мистером Уолтерсом по телефону (212) 558-3131. Строка 12: с его агентом, миссис Кеннеди, можно связаться по телефону +12 (123) 456-7890. Строка 14: С ней также можно связаться по телефону (888) 312.8403, добавочный номер 12.
Поиск в словаре по словам
Программа ниже ищет в словаре любые слова, которые начинаются с h и заканчиваются на pe. Для ввода используется файл словаря, включенный во многие системы Unix, / usr / share / dict / words.
импорт ре filename = "/ usr / share / dict / words" pattern = re.compile (r "\ bh \ w * pe $", re.IGNORECASE) с открытым (имя файла, "rt") в качестве myfile: для строки в myfile: if pattern.search (line)! = Нет: печать (строка, конец = '')
Выход
Надежда гелиотроп надежда хорнпайп Гороскоп обман




